
0. Requisitos
Los que dicen que es imposible no deberían molestar a los que lo están haciendo -Albert Einstein

1. Introducción
Redes Neuronales Recurrentes (RNN en ingles), son actualmente la tecnología mas poderosa que tenemos dentro del aprendizaje supervisado, y ahora vamos a pasar a explicar el porque, porque este algoritmo es tan avanzado, y tan poderoso.
Como habíamos hablado anteriormente, el concepto en el que se basa el deep learning, es tratar de imitar al cerebro humano, y seria interesante asociar a las Redes Neuronales Recurrentes con alguna parte del cerebro humano, y la parte con la que lo asociaremos sera el lóbulo temporal, que es el encargado de la memoria a largo plazo. el lóbulo temporal se encarga de que la información no se pierda a través del tiempo. Por ejemplo, imagina mañana no poder recordar este articulo, solo recordarlo hoy que lo leíste. Entonces las Redes Neuronales Recurrentes se podrían comparar con el lóbulo temporal

No quiero que te esfuerces en entender el porque ahora, déjame desarrollar un poco la idea para que comprendas la razón de forma intuitiva.
Entonces ahora vamos al campo informático. Las RNN, son modelos de Deep Learning, que se alimentan a ellas mismas una cantidad N de veces, es decir, la neurona de salida vuelve a poner el resultado en la neurona de entrada una cantidad N de veces, entonces la representación mas old-school de este proceso es la siguiente.

En donde la entrada es la información que le pasemos, y la salida de la RNN va a ser devuelta a ella misma una cantidad determinada de veces y eso se conoce como Bucle Temporal, pero como dije esta es una representación de la vieja escuela, ahora el enfoque mas moderno para representar este modelo es “desenrollar” el bucle temporal

Algo a notar es que esta representación no es una sola neurona, es una capa completa de neuronas, la red neuronal tiene entradas y salidas, pero algo importante es que las neuronas están alimentándose a ellas mismas a través del tiempo, y de esa forma tenemos una memoria a corto plazo, porque las neuronas recuerdan lo que paso atrás en el tiempo, de alguna forma recuerdan el dato que le pasamos anteriormente, por eso se suele decir que este tipo de redes neuronales corresponden al campo del deep learning con series temporales, y esto les permite pasar información a ellas mismas en el futuro y analizarla.
Vamos a ver algunas de las arquitecturas de RNN, para que vean lo poderosas que pueden llegar a ser, estos ejemplos suelen ser muy comunes a la hora de hablar sobre RNNs

Tenemos la arquitectura One To Many (Una entrada muchas salidas), que como podemos ver aquí, la entrada es una imagen, y la salida es una descripción de la imagen en lenguaje natural. Y para hacer esto se suele alimentar primero a un Red Neuronal Convolucional con la imagen antes de pasarla a la Red Neuronal Recurrente.

Otra arquitectura común es Many to One (Muchas entradas y una salida), y un ejemplo de esto puede ser el análisis sentimental profundo, donde le paso una cantidad de palabras y obtengo una respuesta.

Otra arquitectura común es Many to Many (Muchas Entradas y Muchas salidas), y un ejemplo seria la traducción. Donde le pasamos varias palabras y nos devuelve varias palabras.
Antes de cerrar quiero que vean este cortometraje, donde su guion esta escrito por una RNN que alimentaron con muchos guiones de películas de ciencia ficción, y hicieron que predijera el guion de una película de ciencia ficción, y el resultado es … bastante decente, me gustaria que pusieras atención a los diálogos, porque suelen perder el sentido en ciertas partes de la obra
[embed]https://www.youtube.com/watch?v=LY7x2Ihqjmc[/embed]
2. Desvanecimiento de gradiente
Ahora discutiremos uno de los problemas mas grandes dentro de la arquitectura de las RNNs y es el problema de “Desvanecimiento de gradiente”. Fue descubierto por Sepp Hochreiter’s, y es un problema muy muy grande del que voy a hablar en esta sección.
Tenemos que ir a atrás, y recordar como funciona el algoritmo de descenso de gradiente para encontrar los mínimos globales, debemos recordar que el error va a ser calculado y se va a propagar hacia atrás por la Red Neuronal modificando el valor de los pesos para encontrar una solución optima.
Y lo que pasa en las RNNs es algo similar pero un poco mas complejo.

La información se propaga a través de la Red, y cada salida tiene una función de costo asociada, y se propaga a través del tiempo, recordemos que cada uno de estos nodos no es una neurona, es la representación de una capa completa. Entonces para cada punto en el tiempo, se calcula una función de perdida, es decir todas las salidas de la capa de la RNN, va a ser comparada con la salida real, o ideal, para calcular la función de perdida para luego ajustar los pesos

Y nos enfocamos en C sub t, entonces todas las neuronas involucradas en el calculo tienen que ajustar el valor, para poder calcular la salida y minimizar el error, no se van a actualizar solo las neuronas que están directamente conectadas con cualquiera de las funciones de perdida, tienen que ser todas, y dependiendo de lo grande que sea tu red neuronal y el problema aparece justo en este sector.

Aquí tenemos la formula de como se propaga hacia atrás el error en las RNNs, y esta parte de la formula con la flecha alude a los pesos que conectan las neuronas a través del tiempo, entonces lo que pasa es que estamos multiplicando las capas por los pesos, y lo que pasa es que multiplicamos por el mismo peso todo el tiempo todo el tiempo que necesitemos ir a través de este bucle temporal, y el problema es que cuando multiplicas por un valor pequeño tu valor se hace pequeño de una manera muy rápida, entonces como los valores de los pesos son aleatorios y cercanos a cero, entonces al multiplicarlo muchas veces ese valor va decreciendo.
¿ Que significa esto para la red neuronal ?. Es simple mientras mas pequeño es el valor, mas difícil es para la red actualizar los pesos, por ejemplo si mi valor es grande, la red se va a actualizar mas rápido, y encontrara los mínimos globales mas rápido, pero si mi valor es pequeño se va a demorar mucho mas tiempo. Entonces quizás entrenes por muchas épocas una red neuronal y no tengas resultados óptimos, por consiguiente las capas del principio de la red van a estar entrenadas y las capas del final no estarán entrenadas, y el problema real es que las primera capa se usa de entrada para las demás. Entonces se va a entrenar la red completa con entradas que provienen de una neurona no entrenada, entonces entras en un circulo vicioso, donde llegas al final y la red se entrena, pero propagas el error y vuelves a comenzar con una red no entrenada.
y la solución a este problema se encuentra en el algoritmo de LSTM (Long Short Term Memory Networks), y es lo que discutiremos ahora.
Te invito a leer el siguiente paper de Razvan Pascanu si quieres informarte mas de este problema
https://proceedings.mlr.press/v28/pascanu13.pdf
3. LSTMs
En esta ocasión voy a pasar a usar las imágenes de uno de los mejores blogs de este tema, que leí hace mucho tiempo, y me dejo bastante claro la idea detras de las LSTMs
Material Original
Entonces las RNNs se ven de la siguiente manera

ya discutimos el problema de estas redes, pero esta es una representación que me gusta mas que la anterior de las RNNs, y quiero que veas que así se ve la RNN estandar y ahora así se ve la LSTM.
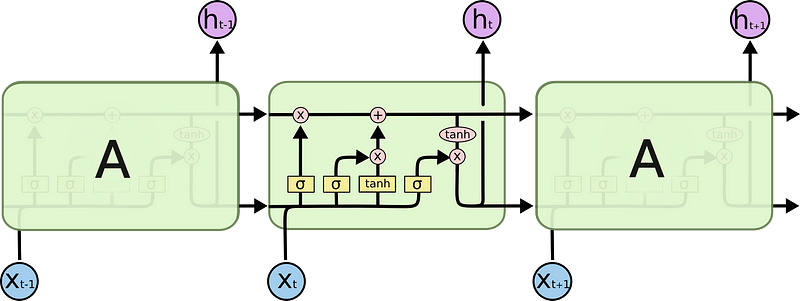
Y quizás estés pensando, que esta representación es muy compleja, pero en verdad es un poco mas compleja de una RNN, pero vamos a ahondar en esta arquitectura y veras que podrás sentirte cómodo al poder ver y explicar esta imagen.
antes hacemos referencia a Wrec (peso recurrente).

En este caso esta linea representa al peso recurrente, y como puedes observar, no se le aplican muchas operaciones, solo dos operaciones punto a punto, por lo que el valor del peso recurrente no se toca demasiado.
Y si ves la imagen anterior te darás cuentas que este peso recurrente, va a través del tiempo, y cada celda representa un tiempo pasado o futuro, y como ves a información fluye prácticamente libre por la red, y eso es bueno, porque al momento de hacer la propagación hacia atrás no tendrás el problema de desvanecimiento de gradiente, esa es la esencia de las LSTM.

Aquí tenemos una representación de una celda LSTM, donde los valores de C, son los correspondientes con la memoria, los H son las salidas, y X, es la entrada, por lo que tenemos 3 entradas y dos salidas que son C sub t y H sub t, algo importante a destacar es que todos los valores son vectoriales.

y las leyendas, que son importantes de entender, cada rectángulo amarillo, es una capa neuronal, y encima lleva escrita su función de activación, Sigma es el simbolo de la “Funcion Sigmoide”, y “Tahn” recordemos que es la función de Tangente Hiperbólica, y la “Flecha” es para transferencia de vectores, las dos ultimas son para Concatenar vectores y Copiar vectores, algo a notar es que las concatenaciones, no son combinar nuestros valores, es mejor decir que son procesos llevados a cabo en paralelos, pero igual siguen estando separados, y lo mas interesante son las Operaciones Punto a Punto, las “operaciones con X” son válvulas, y se llaman así, porque bloquean el paso de información o lo permiten, literal como un grifo y las “Operación con +” imaginara como una “Válvula en forma de T”, así se le puede agregar memoria adicional a la salida, ahora vamos paso a paso.

Aquí tenemos un valor de X y la salida anterior que entran y se concatenan y aplicando la Funcion Sigmode arroja un valor por medio del cual se decide abrir la “Válvula”, que se abra no significa que pasen todos los valores, siempre pasan algunos valores por eso esta “válvula” se llama la “válvula de olvido” porque se clasifica la información que si o si aporta a la eventual salida

Luego se hace una segunda clasificación, para decidir si hay otros valores que deben pasar o no, y en caso de que si pasen, se combinan con la salida o son olvidados.
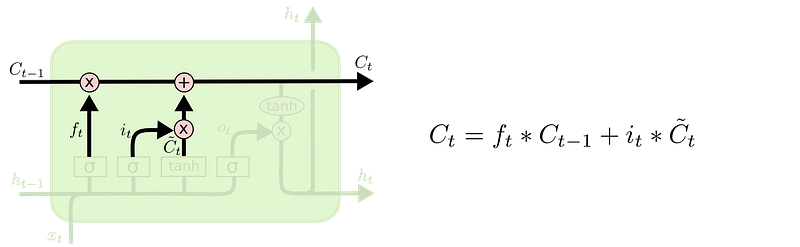
Y como habíamos dicho, luego los valores fluyen por la memoria a la siguiente celda.

y por ultimo se toma la parte de la memoria y con estas ultimas dos operaciones, se decide que partes del resultado van a ser la salida, osea si la salida tiene que ser toda la información que contiene la memoria, o solo una parte.
si quieres profundizar mas en esta explicación, visita este link
Understanding LSTM Networks
La inteligencia consiste no sólo en el conocimiento, sino también en la destreza de aplicar los conocimientos en la práctica.

4. Implementacion de una LSTM con Tesorflow Keras API: Limpieza de datos
Vamos a implementar un modelo de Redes LSTM para predecir los precios de Stock, de Google, vamos a ir paso a paso, detallando cada uno de los mismos, ahora vamos a descargar el siguiente dataset:
Google_Stock_Price_Train.csv
Google_Stock_Price_Test.csv
Ahora vamos a ir paso a paso por la limpieza de datos y vamos a comenzar importando las siguientes librerías, recomiendo entrenar la red como siempre en:
Google Colaboratory
Si quieres configurar las GPU y saber como utilizar esta plataforma favor de revisar el articulo anterior:
[embed]https://medium.com/@jcrispis56/una-introducci%C3%B3n-completa-a-redes-neuronales-con-python-y-tensorflow-2-0-b7f20bcfebc5[/embed]
Vamos a comenzar importando Pandas y Numpy, para manipular nuestros datos fácilmente, para ello corremos la siguiente linea de código

Aquí estamos importando las librerías Pandas y Numen bajo el alias np y pd respectivamente.

Ahora cargamos el archivo con los datos de entrenamiento en un objeto DataFrame para poder trabajar, con el.

Con este comando se mostraran los primeros 5 resultados, en este caso vamos a tomar el valor “Open”, de nuestros datos con el fin de predecir este valor.
Date Open High Low Close Volume 0 1/3/2012 325.25 332.83 324.97 663.59 7,380,500 1 1/4/2012 331.27 333.87 329.08 666.45 5,749,400 2 1/5/2012 329.83 330.75 326.89 657.21 6,590,300 3 1/6/2012 328.34 328.77 323.68 648.24 5,405,900 4 1/9/2012 322.04 322.29 309.46 620.76 11,688,800

Ahora lo que haré va a ser seleccionar las primeras dos columnas, para ello usare el método “iloc”, y le pasare este valor dentro de corchetes [:,1:2] esto lo que nos esta diciendo es:
- “:,” en el axis = 0, no quiero seleccionar ni un valor.
- “1:2” en el axis = 1, quiero tomar la columna que esta entre los indices 1:2, pero también podríamos decir simplemente :,1, pero si lo hacemos así nos va a devolver un array de 1 dimensión, pero de esta forma 1:2, nos retorna un array de dos dimensiones.
Ej:
dataset_train.iloc[:, 1].values[:5]
Out: [325.25 331.27 329.83 328.34 322.04]
dataset_train.iloc[:, 1:2].values[:5]
Out: [[325.25] [331.27] [329.83] [328.34] [322.04]]
3. “.values” quiere decir que quiero que me devuelva los valores en una Array de Numpy
Si pusiste a la explicación de como funciona la LSTM, te habrás dado cuenta que utilizan las capas de Tahn y Sigmoide, que si hacemos un recuento necesita valores pequeños para funcionar, por lo que necesitamos pasar nuestros valores grandes, a valores entre “0 y 1”, para eso usaremos ScikitLearn.

Entonces vamos a usar el MinMaxScaler, que va a normalizar de nuestros datos con la siguiente operación.

Ahora vamos a inicializar, nuestro MinMaxScaler:

feature_range = (0,1) significa que quiero mis valores de salida estén entre 0 y 1

y aplicamos la función en nuestros datos, y el antes y después seria así
Antes de escalar [[325.25] [331.27]] =========== Despues de escalar [[0.08581368] [0.09701243]]
de esta forma nuestro algoritmo funcionara mejor, y el ultimo paso es armar la matriz X e Y, y la mejor predicción se obtuvo prediciendo el día siguiente, a partir de los 60 días anteriores, así que, quiero almacenar 60 valores anteriores en X, y en Y almacenar el día 60 + 1, para ello vamos a hacer lo siguiente:

Vamos a inicializar dos listas vacías, y aquí vamos a usar la lógica, necesito tomar 60 días anteriores, y predecir el día siguiente, y así para el largo del dataset, entonces lo mas conveniente, es empezar por el día numero 60, entonces siguiendo esta lógica, nuestra matriz tomara del día “i = 60, 61, 62” y eso le restaremos 60 días por lo que si el día es = a 60 y le restamos 60 empezaremos en el día 0, hasta i, es decir tomar exactamente 60 valores y el “,0” es para separar el una dimensión distinta cada uno de estos 60 valores, y el valor de y_train tiene que ser el propio i y no i + 1, porque si empezamos a contar del 0, nuestro i corresponde al día 61.

y ahora lo que vamos a hacer es convertir nuestras listas en arrays de numpy.
Forma de X: (1198, 60) Forma de y: (1198, 1)
teniendo como resultado 1198 arrays de 60 valores cada una como entrada y 1198 arrays de 1 valor como salida esperada
5. Armando Probando y Analizando Resultados de Nuestro Modelo
Nuestras capas LSTM necesitan entradas de 3 dimensiones, y en este caso nuestro Array X tiene solo 2 dimensiones, según la documentación oficial de Keras, la forma que se espera de nuestros datos de entradas es la siguiente
3D tensor with shape
(batch_size, timesteps, input_dim).Donde el primer valor, es la cantidad de datos, el segundo, es la cantidad de pasos temporales, en este caso 60, porque a partir de 60 pasos temporales predecimos el siguiente, y la cantidad de indicadores que tenemos en nuestros “timesteps” en este caso 1 porque tomamos una columna, pero pueden ser mas, solo tienen que recordar especificar cuantos indicadores le están pasando a la capa. Por lo que para respetar el formato usare la función reshape de numpy, para agregarle la tercera dimensión, que corresponde a los indicadores.

Entonces como no necesito cambiar nada, usare las dimensiones que ya tiene nuestra array que son la cantidad de datos y los timesteps, solo le agregare los indicadores o input_dim.

La inicializacion del modelo me la salto, pero recalcar solamente que le llame “regresor” y es solo porque vamos a predecir valores continuos, y eso es hacer una “regresion”.
Ahora algo importante a notar es que el primer argumento que recibe nuestra capa LSTM es la cantidad de unidades de memoria que va a tener esta capa de LSTM, que lo vimos mas arriba, y return_sequences, se tiene que setear en “False” solo si la siguiente capa no es una capa LSTM, es decir, para poner dos capas LSTM seguidas necesitamos poner el argumento return_sequences = True, o si no lanzara un error, y el input_shape solo recibe las dos ultimas dimensiones porque es lo que se conoce en el álgebra lineal como Tensor, y la primera dimensión de un Tensor, es variable y se corresponde con nuestra Cantidad de Datos.

Ahora agregaremos dos capas mas, solo la entrada tiene que especificar las dimensiones de nuestros datos, por lo que podemos omitirla en las capas siguientes. Y la ultima capa tiene que ser siempre una capa normal para la salida, eso ya lo hemos visto antes.

Y vamos a compilar con el Optimizador Adam, y la función de perdida para nuestro Back Proagation sera El Promedio de Los Errores Al Cuadrado, que ya la vimos en el primer articulo:
[embed]https://medium.com/@jcrispis56/una-introducci%C3%B3n-completa-a-redes-neuronales-con-python-y-tensorflow-2-0-b7f20bcfebc5[/embed]
Ahora lo vamos a entrenar.

Una vez entrenado, a mi me dio los siguientes resultados
Loss: 0.0013
Acc: 0.0017
Ahora vamos a hacer la predicción del dataset de prueba.

Ahora voy a hacer lo mismo que hice con el dataset de entrenamiento, solo que con una variación, lo que haré es fusionar todas mis filas del dataset de prueba y entrenamiento en uno solo, en una única columna, porque el dataset de prueba contiene solo 20 valores, y quiero tomar las secuencias de 80 días, para respetar la estructura de mis datos, por ello haré lo siguiente.

Mis inputs, van a comenzar en el indice correspondiente al largo del dataset completo, menos el dataset de prueba menos 60, para respetar el formato, de esta forma tomare 80 días para predecir, y lo convertiré a 2 dimensiones y normalizare los valores.

Repetimos exactamente el proceso anterior, y predecimos nuestros valores, y la mejor forma de ver las predicciones de este tipo de modelos es graficando, y y tomando como eje X el tiempo, y el Y el valor real vs. el valor precedido, para ello importaremos Matplotlib

Si estas en Jupyter Notebook te recomiendo poner el comando de “Celda Magica” para que te muestre los gráficos en el “Notebook”.

y haremos nuestro Gráfico, del cual no explicare muy bien, puedes mirar la documentación, pero dejare la Visualización para una serie que comenzare luego de esta. Y nos muestra el siguiente resultado

Algo importante de explicar, es que nuestra Red, pudo predecir las alzas y bajas, pero lo que no pudo predecir es las alzas bruscas y bajas bruscas, pero esta bastante bien, pero te invito a agregar mas factores que influyan en este proceso, pueden ser incluso precios en bolsa de otras empresas relacionadas, tienes un mundo de experimentos para hacer, y conseguir datos de Stock reales con python es bastante simple con la siguiente librería:
Quandl Python Wrapper
6. Agradecimientos
Si este documento te gusto, y te sirvió, y aprecias mi trabajo no dudes en compartirlo con toda la gente interesada del tema, para que se enteren como manejar correctamente las redes neuronales recurrentes, ya que actualmente son las herramientas mas ocupadas en el Deep Learning, con esto igual le doy cierre al Deep Learning Supervisado, para pasar a ver un poco de lo básico de Deep Learning no Supervisado, así que espera las siguientes partes, vienen interesantes, sin mas que decir, gracias, y adiós.
Comentarios
Publicar un comentario